01 什么是重复内容
比你想的更宽泛,也比你想的更常见
想象一下:你走进一家书店,想买一本书,但货架上摆着三本封面几乎一模一样的书,店员也说不清哪本是正版、哪本是修订版、哪本是盗印版。你会怎么办?很可能转身离开,或者随便拿一本,而店家也因此损失了向你精准推荐的机会。
搜索引擎面对重复内容时,遭遇的正是同样的困境。
重复内容(Duplicate Content)指的是互联网上在多个不同 URL 下出现的相同或高度相似的内容。这个定义看似简单,但实际边界远比"完全一样"要宽得多。搜索引擎爬虫在判断两个页面是否重复时,依据的不是人眼看到的视觉效果,而是页面的底层源代码结构。
爬虫视角 vs 人眼视角
爬虫无法"看"到你精心设计的页面样式、图片和交互动效——它们读取的是 HTML 源代码。两个页面视觉差异再大,只要代码结构、标题标签(title/h1)、正文内容高度相似,爬虫就可能判定为重复。
以 Moz 的判定标准为例,当两个页面的代码相似度达到或超过 90%,就会被标记为重复内容。但不同工具、不同搜索引擎的阈值略有差异,有时相似度在 70%~80% 之间的页面也会引发问题,这取决于重复部分是否集中在最核心的内容区域(如标题、摘要、正文开头)。
值得注意的是,重复内容本身通常不会让 Google 直接对你的网站施以惩罚(除非是明显的恶意抄袭)。它的危害更多体现在"机会成本"上——排名被稀释、爬虫预算被浪费、最该排名的页面却没能获得足够的权重积累。

02 为什么对排名危害如此之大
三种核心伤害机制,缺一不可的理解
很多站长低估了重复内容的破坏力,原因在于它的伤害不是即时的,而是持续性的慢性消耗。以下三个机制解释了它究竟如何拖累你的SEO表现。
排名信号被稀释
当多个URL拥有相似内容时,外部链接、点击信号、停留时长等排名权重会分散到这些URL之间,而不是集中到最优质的那个版本。以同款商品的不同颜色页为例,如果有20个外部链接分别指向这5个颜色页,平均每页只有4个外链——但如果合并为1个规范页面,它就能拥有全部20个外链的权重,竞争力完全不同。
爬虫预算被浪费
搜索引擎给每个网站分配有限的"爬虫预算"(Crawl Budget),即每次抓取愿意访问的页面数量。当爬虫把大量时间花在重复页面上,你真正有价值的新内容、核心产品页、重要落地页,可能等不到被爬取就被跳过了。对于大型电商网站或内容平台,这个问题尤为突出。
搜索引擎选错排名页面
即便搜索引擎决定只收录你的页面之一,它选择的版本未必是你希望展示的那一个。你精心优化了A页面,结果搜索引擎把B页面排在前面——而B页面的标题、描述、内链结构都远不如A。这种"选错版本"的情况会直接拉低点击率和转化效果。
03 重复内容的七大常见来源
很多都是系统自动产生的,你可能完全不知情
重复内容的来源往往出乎意料。除了人为的复制粘贴,更多的是网站技术架构、CMS系统设置、URL参数等自动化机制在悄悄制造麻烦。
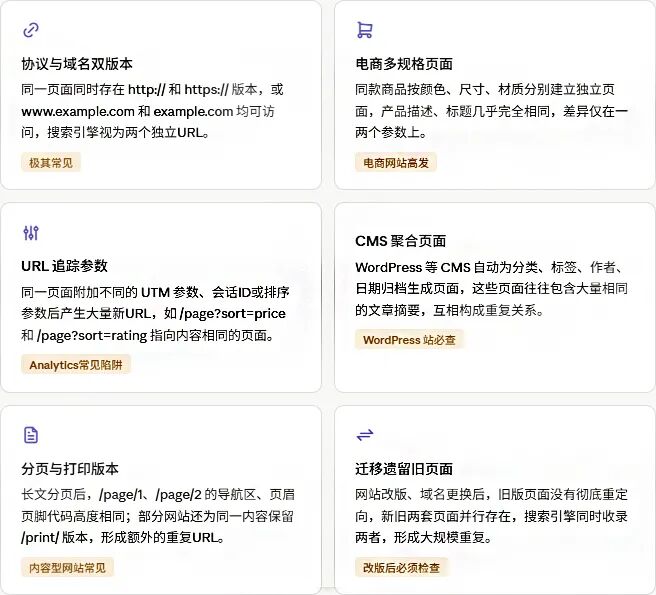
特别提示
上述来源中,协议双版本和 CMS 聚合页面是最容易被遗忘的,也是规模最大的。一个中型 WordPress 博客,仅分类+标签+作者归档页就可能产生数百个重复页面,远超实际内容页的数量。
04 如何检测与定位重复页面
发现问题是解决问题的前提。好消息是,重复内容虽然隐蔽,但有成熟的工具和方法可以系统性地将它找出来。
爬虫类工具
Moz Site Crawl、Screaming Frog、Sitebulb 等工具可以模拟搜索引擎爬取整站,自动计算页面相似度并分组标记重复对象。推荐将导出数据中的"重复分组标识符"作为优先处理依据——同一分组编号下的所有 URL 互为重复。
Google Search Console
在"覆盖率"报告中,留意"重复页面——用户未指定规范网址"和"重复页面——Google 已选择其他规范网址"两类问题。后者尤为重要:它意味着 Google 无视了你设置的 canonical,自行选择了另一个版本作为主页面。
拿到报告后,建议按以下顺序处理数据:
按重复分组筛选,找出规模最大的分组
同一分组内 URL 数量越多,说明问题越系统性,通常对应某个技术层面的设置错误,修复一处可解决整批问题。
识别每组的"最优版本"
通常是流量最高、外链最多、内容最完整的那个URL,它将成为你要保留和强化的规范版本。
确认当前 canonical 标签是否正确指向最优版本
很多网站的 canonical 已设置,但指向了错误的URL,或者由于 CMS 插件冲突被覆盖。用工具逐一核验实际渲染的 canonical 值。
对照解决方案矩阵,逐组制定处理方案
不同来源的重复内容需要不同的解法,参见下一节的详细说明。切勿对所有重复页面一刀切地使用同一种方案。
一、301 永久重定向
301 重定向会将用户和搜索引擎从旧URL永久引导到新URL,同时将绝大部分(约90~99%)的排名权重转移给新版本。旧URL在搜索引擎中逐渐被删除,新URL继承所有积累的权威度。这是最"干净"的解法,适合旧页面完全没有保留价值的情况。
典型适用场景:HTTP 升级为 HTTPS 后的旧协议页面、域名迁移后的旧域名页面、内容大幅更新后不想保留的旧版本文章、子域名整合到主域名时的旧子域页面。
注意:301 重定向链不要过长,超过3跳的重定向链会显著减缓爬取速度,也会导致权重在传递过程中有所损耗。定期检查并"压平"重定向链。
二、Canonical 规范标签
在页面的 <head> 区域添加 rel="canonical" 标签,告诉搜索引擎哪一个URL是这批相似页面中的"主版本",排名权重应集中给它。被标记了 canonical 的非主版本页面依然可以被用户正常访问,也可以被爬虫抓取,但不会参与排名竞争。
典型适用场景:电商网站的商品多规格页(不同颜色、尺寸的URL,canonical 均指向默认规格页)、内容需要多个URL分发但希望排名集中的落地页、内外部链接指向带参数版本但规范版本不带参数的情况。
注意:Canonical 标签是"建议"而非"指令",Google 有权在特定情况下忽略它。如果你发现 Google 一直不遵守你的 canonical 设置,通常说明规范页面本身的权重或质量不如它指向的来源页,需要先强化主版本。
三、Meta Noindex
在页面 <head> 中添加 <meta name="robots" content="noindex">,告诉搜索引擎:你可以爬取这个页面,但请不要将它纳入索引。这意味着该页面不会出现在搜索结果中,也不会参与排名,但它对内部用户仍然完全可访问,也可以被其他页面正常链接。
典型适用场景:分页页面(/page/2 及之后的页面)、带筛选条件的结果页(价格区间、品牌筛选等)、站内搜索结果页、感谢页/确认页、内部测试或预览页面。
注意:Noindex 与 Disallow(robots.txt)有本质区别:Disallow 阻止爬取但允许收录;Noindex 允许爬取但阻止收录。对于需要阻止收录的页面,请优先使用 Noindex 而非 Disallow,否则爬虫无法读取到 noindex 指令本身。
四、补充差异化内容
有些页面被判定为重复,并不是因为它们"应该合并",而是因为内容写得太薄、太雷同。如果两个页面本来就应该是两篇独立的内容,那么正确的解法不是删除或合并,而是为每个页面挖掘真正差异化的角度——不同的目标用户、不同的使用场景、不同的数据支撑、不同的案例故事。
典型适用场景:同一产品线的不同型号产品页(功能差异本应是卖点,却写成了一样的介绍)、面向不同城市或地区的服务页(只替换了城市名,其余完全相同)、针对不同用户群体的功能介绍页(内容本应差异化但写法雷同)。
判断标准:如果删掉这个页面,用户会损失真正有价值的信息吗?如果答案是"不会",考虑合并;如果答案是"会",那就把这个"有价值的差异"真正写出来,而不是留在你的脑子里。

文章为作者独立观点,不代表DLZ123立场。如有侵权,请联系我们。( 版权为作者所有,如需转载,请联系作者 )

网站运营至今,离不开小伙伴们的支持。 为了给小伙伴们提供一个互相交流的平台和资源的对接,特地开通了独立站交流群。
群里有不少运营大神,不时会分享一些运营技巧,更有一些资源收藏爱好者不时分享一些优质的学习资料。
现在可以扫码进群,备注【加群】。 ( 群完全免费,不广告不卖课!)



![[快讯]Google发布2026年5月核心算法更新](https://cdn.dlz123.cn/uploads/images/2026-05-24/sz_mmbiz_jpg/UrQ0u8YMicLfwmEDPoTYAeHkU9nZE2pLjibgvcjRgOeZaZcy8rQsff0wJwfSCiaTwW1ZfzecWPdQXS1yOlLAbqySGEibc1VxOq6bOZAtrHOrzDs.jpeg&from=appmsg?imageMogr2/thumbnail/!30p)



发表评论 取消回复