上一篇讲了用 Ctrl+U 查看页面源代码,这是最直接的方式,但有一个局限:它验证的是"服务器给所有人返回的HTML",无法模拟特定爬虫身份。 有些网站会根据请求者的身份返回不同内容,比如识别到爬虫后返回完整SSR,识别到普通用户后返回CSR版本。Ctrl+U无法区分这种情况。 这时候需要用curl命令,直接模拟爬虫身份发请求。 curl是Windows和Mac系统自带的命令行工具,不需要安装。 按 Win+R,输入 cmd,回车,打开命令提示符,输入: 按 Command+空格,输入"终端",回车,输入: 命令里三个部分的作用: 建议每次技术改动上线后,按以下矩阵完整测试,填写✅或❌: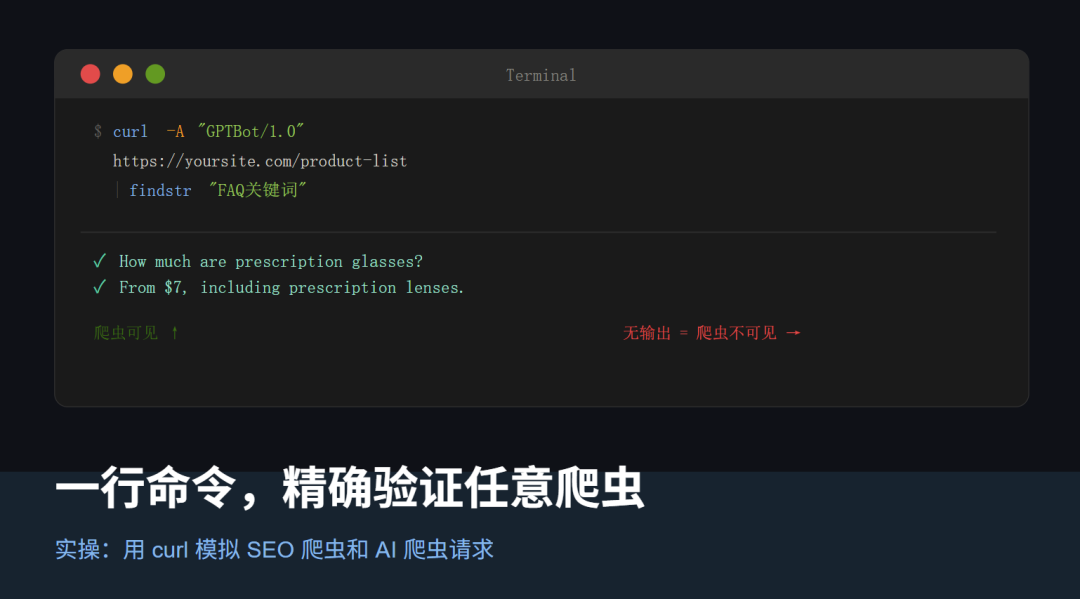
curl命令的基本格式
Windows用户
Mac用户
主要爬虫的UA字符串
SEO爬虫
AI爬虫
完整命令示例
模拟Googlebot请求列表页
模拟GPTBot请求文章页
如何判断结果
建立验证矩阵
文章为作者独立观点,不代表DLZ123立场。如有侵权,请联系我们。( 版权为作者所有,如需转载,请联系作者 )

网站运营至今,离不开小伙伴们的支持。 为了给小伙伴们提供一个互相交流的平台和资源的对接,特地开通了独立站交流群。
群里有不少运营大神,不时会分享一些运营技巧,更有一些资源收藏爱好者不时分享一些优质的学习资料。
现在可以扫码进群,备注【加群】。 ( 群完全免费,不广告不卖课!)







发表评论 取消回复